Semantic Diffusion Adapter
At Can of Soup, I worked extensively with the challenges of incorporating multimodal inputs to image generation. This project is just one example, where I built and trained a unique model for briding natural input images into the Flux diffusion model, while recreating their layout and scene faithfully, and with some ability to then edit or manipulate that scene in the semantic space.
See a broader list of my work at CanOfSoup here.
This project demonstrates the following contribution to diffusion-based editing of natural images: instead of training a diffusion model to internally balance reproduction of the original image and its layout with the task of altering it according to a prompt, it is possible to create a purely semantic—and yet spatial—representation of the image that is amenable to editing by an LLM, but also sufficiently complete to facilitate quality reproduction of the original scene. By training an adapter to produce an embedding of natural images with a frozen Flux model as decoder, and additionally training a decoding language model to alter the embedding in discrete editing tasks, this work indicates that images may be meaningfully edited purely within a semantic representation.
Overview
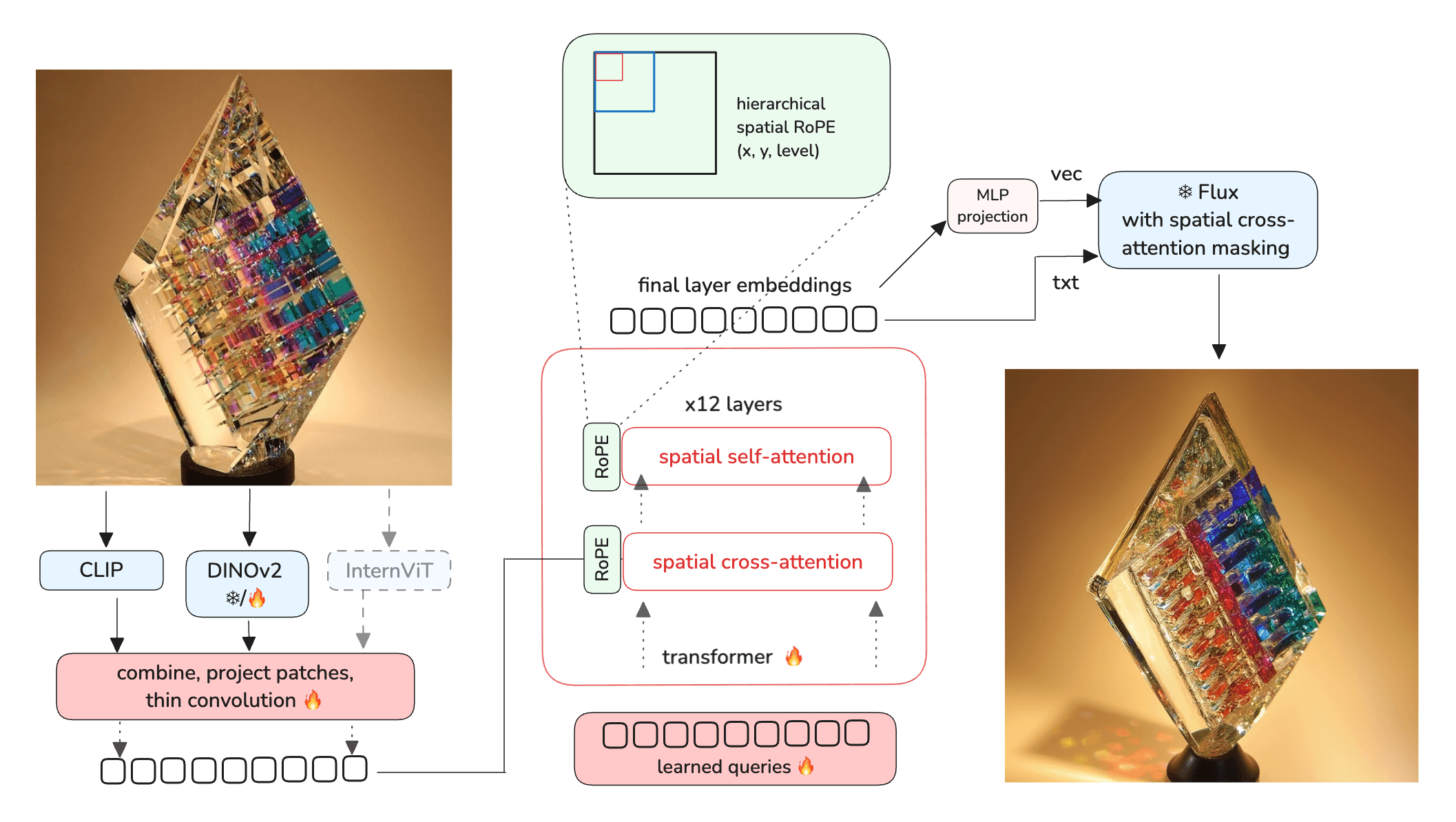
The model architecture can be thought of as essentially a kind of auto-encoder that encodes images into a semantic and hierarchically spatial embedding, which can then be decoded by a frozen diffusion (Flux) model.
| original | reconstruction | |

|
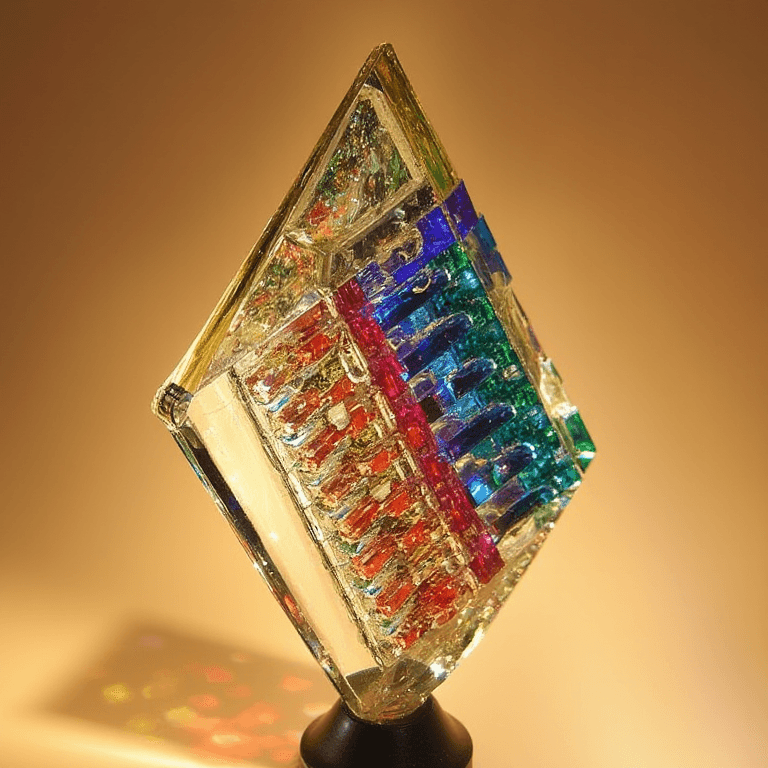
|
Example results of input (natural) images and resulting reconstructions when the adapter's output embedding is fed to frozen Flux. Overall scene and layout reconstruction is strong, as well as stylistic replication. Person / face identity is not as exact, partly due to the relatively smaller size of faces in images and training data. However, this project's objective was not focused on person identity, since we were training a separate ID adapter in parallel to handle transposition of faces. |

|

|
|

|

|
|

|

|
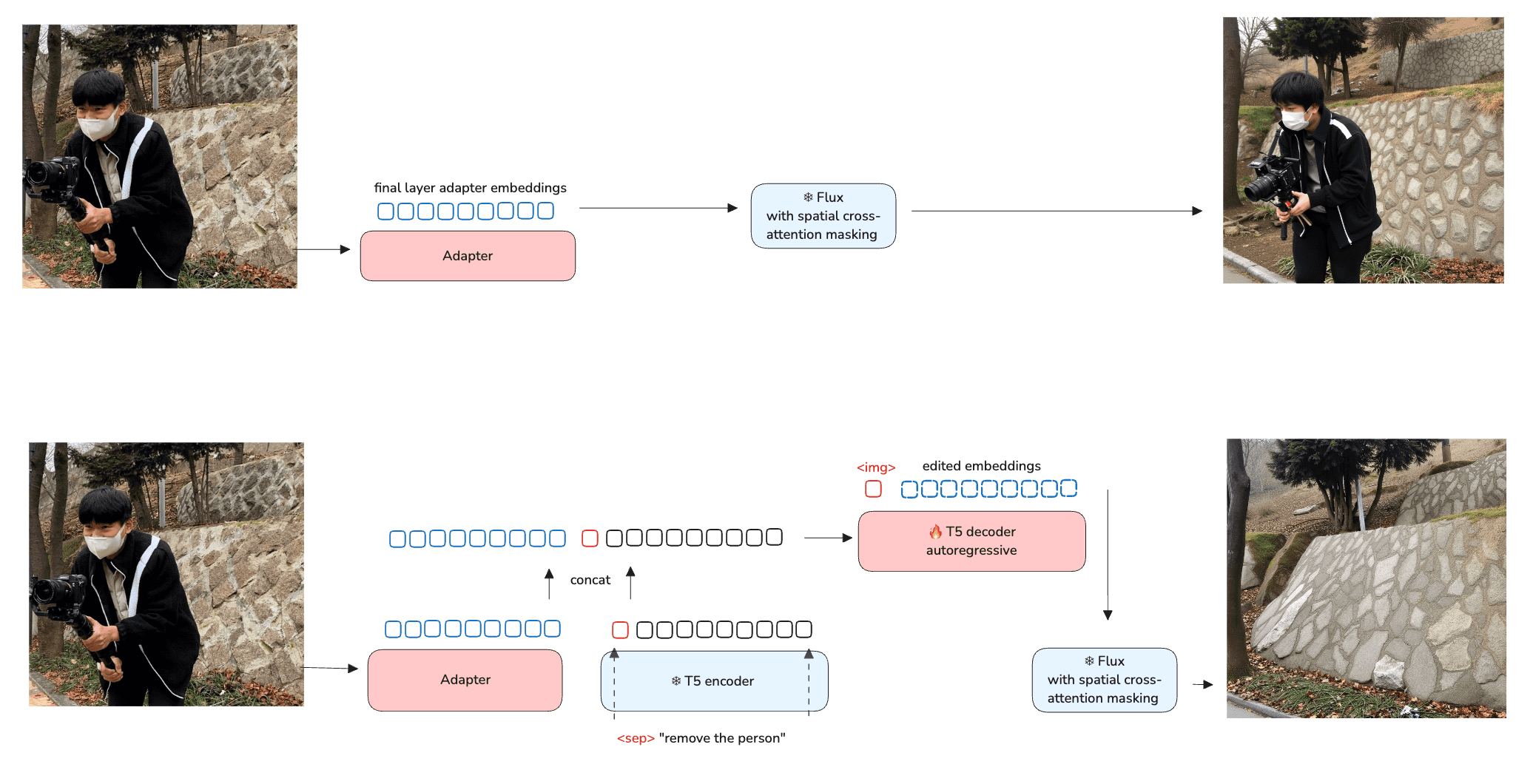
A goal of the model is not merely to reproduce images, but to create a kind of embedding of the scene which is amenable to editing by training a language model. In the editing experiments conducted, I trained only the decoder half of a T5 model to produce an edited embedding given the adapter’s output concatenated with an embedding of an instruction.
Training was conducted on 32+ H100s, depending on the project phase, with an expansion from a base of only 16 embedding positions to later phases with 112 or more positions according to hierarchy of patches (see discussion below). Training during early phases was locked at 512 since resolutions below this floor behave poorly with Flux, and expanded to higher resolutions in late training.
Background discussion
There are several commonly used approaches for recreating & altering a natural image via diffusion, with varying limitations.
Adding source latents
One method is to directly add the source image’s vae-encoded latents alongside the noised target latents as an input to diffusion, either as additional channels that run through connected, separately tuned blocks (among which are ControlNet-based editing models) or by combining the original latents and noised latents at an early step, fusing via an addition or other thin projection.
This is arguably the oldest approach to constructing an “editing model,” where the existing diffusion unet or DiT is retrained to denoise in the context of additional source image latents; it must then learn to combine the prompt input (which will be partial, eg “wearing a hat”) with the source image input latent. But it can be poor at the prompting level, due in most cases to the selection of older text models (eg. CLIP, but even T5’s encoder) which are not tuned for an instruct-like syntax with editing or action phrases like “make them older” or “remove the dog”
As a consequence, some of the smarter additions to this structure involve learning a task-specific response, eg. by having learned task embeddings for specific scenarios like adding object versus change style, and letting those task vectors influence the entire network (see Emu Edit for one example: https://arxiv.org/pdf/2311.10089). Even while arithmetic combinations of task embeddings (extending them to new tasks) is possible and offers one path of flexibility, any edit model constructed on this basis will have highly sensitive inference-time parameters to tune, typically including some kind of image fidelity scalar to adjust the balance between input image and prompt. This makes them inflexible, and reveals that the combination of source image and editing instruction is not well joined or integrated, remaining more of a scaled mixture.
Noise inversion
Noise trajectory inversion (DDIM inversion, etc) is another approach that offers to directly reconstruct the source image in the forward diffusion process, without altering the base model. But while continued innovations in inversion sustain it as an interesting area of research (for instance, new ways of aligning the forward/backward paths), the key problem with editability of inversion via prompting is that fidelity to the original image is mostly a kind of controlled coincidence, rather than a semantic relationship: we know that we can reach the target image from a certain starting noise or path, and then diverge minimally from that path towards the influence of a new prompt—but the balance between fidelity and edit are ultimately controlled once again by various inference-time scalars which manipulate the level of divergence from the original trajectory.
Trained cross-attention or adapter
Another approach is by training cross-attention (eg. an IP Adapter) to attend to a semantically encoded image input (typicall a CLIP model). In some cases, using the patch embeddings from CLIP (rather than global or otherwise projected non-spatially) directly can even allow some composition to be preserved, but this layout comprehension is inherently more difficult to preserve in the case of DiT-based non-convolutional models like Flux (often the papers will give a false impression by picking source images that are well-known to the training prior of the models, like Starry Night).
One variation is ELLA/EMMA, which adds timestep-aware modulation and moves the training to an external adapter, hijacking the original text embedding input rather than training new attention layers or heads, keeping all parts of the diffusion model frozen; this comes a bit closer to my approach outlined later. EMMA offers a unique ability to combine modalities intelligently via gated connections in the adapter, but its ability to reproduce the layout of source images is still weak.
My alternative: “semantic” inversion
The goal of my project was to explore another pathway of converting images to latent space — by keeping the entire Flux (dev) model frozen, and training an adapter to convert natural images into a single embedding (in the T5’s input space, on which Flux was trained) that is complete enough to recreate the source images, when provided as the contextual input to Flux in place of a T5-encoded prompt.
The basic model architecture followed the QFormer approach of a transformer with learned query positions, cross-attention to projected embeddings of image patches, and separated heads for self-attention. The depth was 12 layers, and in early training, the number of output embedding positions was capped at 32, but geometrically increased as additional depth levels were added using spatial rendering (see below).
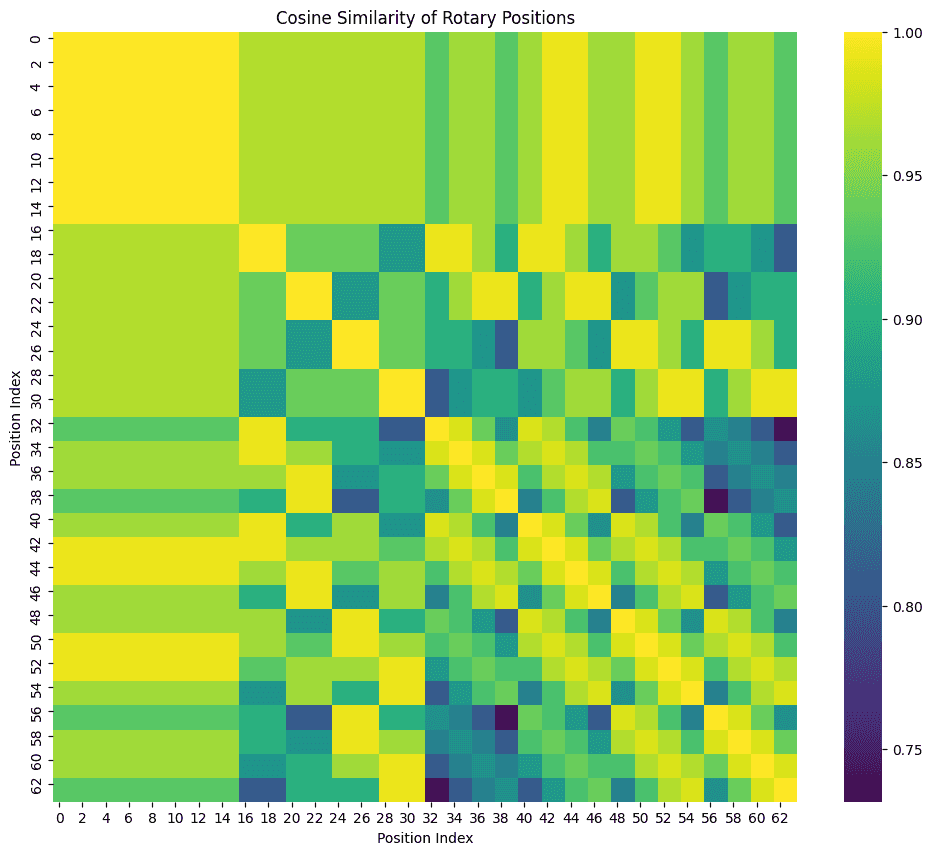
In order to keep the different positions of the queries from converging to a trivial global embedding of the image, a mild penalty was added to discourage cosine similarity of the output embedding positions.
This approach may be thought of as a variation of full “prompt inversion” (finding a continuous prompt embedding that, when provided to the diffusion model, will recreate a close version of a particular source image) and shares some similarities with ELLA/EMMA in an alternative context of Flux, but with several key differences.
Adding vision to CLIP encodings with DINO
For encoders, I used several combinations, including a medium to large CLIP (ultimately a DFN CLIP), InternVL’s encoder in some variations, and always an additional DINOv2. Several papers including (https://arxiv.org/pdf/2401.06209) have shown that more vision-level DINO models can help mediate some of the limitations of semantic CLIP patch embeddings when integrated. The several input embeddings were aligned by patch and projected by a small MLP a shared embedding to be cross-attended to by the main transformer. In later training at higher resolution, the last several layers of the DINOv2 model were unlocked.
Spatial hierarchical embedding
Since the goal is scene and layout recreation, not merely to remix content without regard to form (as various adapters already do well, including the recent official Flux.1 Redux adapter for image variation), the embedding produced by the adapter should have a spatial information, while avoiding the disjointed nature of something like a single-level grid of CLIP patches alone.
Flux natively treats its text-embedding contextual input as a flat sequence without position embedding, but it is trivial to add a custom masking mechanism to Flux’s single and double blocks so that individual positions in the conditioning input sequence can be attended to by only overlapping target patches of the latent. After training 32 “global” embedding positions to capture the content of the source image, I divided the grid into 4 quadrants and added additional embedding positions (expanding the QFormer queries) for each quadrant, with 8 per quadrant to make an additional 32 positions. Then, additional sub-quadrant positions were similarly added, to form a 3 part hierarchy and 128 total positions in the largest variant trained (although the same hierarchy with only 64 total positions was also very effective at reproduction).
The cross-attention masking added to Flux ensured that embedding positions are only attended to by overlapping latent patches. But that’s insufficient for the transformer itself to learn the spatial relationships, so I used a 3-dimensional RoPE to add positional information to the adapter model’s attention to source embedding patches—where the third dimension is the level/depth.
A semantic encoding space
Not only is the encoding spatial and layout-aware due to the hierarchy of embeddings, but it also retains semantic qualities due to freezing the Flux model. Since Flux was trained on the output of a T5 encoder, this ends up constraining the output of the adapter model to the same semantic space. Example outputs below illustrate the level of general fidelity.
| original | reconstruction | |
|
|
|
Example results of input (natural) images and resulting reconstructions when the adapter's output embedding is fed to frozen Flux. Overall scene and layout reconstruction is strong, as well as stylistic replication. Person / face identity is not as exact, partly due to the relatively smaller size of faces in images and training data. However, this project's objective was not focused on person identity, since we were training a separate ID adapter in parallel to handle transposition of faces. |
|
|
|
|
|
|
|
|
|
|
|
The recreation of inputs is then very spatial and preserving of layout, but also thoroughly semantic rather than a visual encoding. This gives the result some potential for additional manipulations, which were explored in various forms, only a couple of which I can mention here.
Tranformation experiments
Several algorthmic experiments showed some potential. For instance, even a simple interpolation between the embedding of 2 images can produce more interesting results than expected:
| Input 1 | Input 2 | Interpolated result |
|
|

|

|
Interpolation, however, does not extract the flexility and targeted editing desired. For the following experiments (which stopped at adding/removing elements, though much more could be done), I took the adapter’s embedding and concatenated it with a frozen T5 encoding of an instruction (“remove the person”), then used that as input to a T5 decoder which was autoregressively trained to output the new embeddings with the desired changes.
This worked well enough to see additions and removals functioning. Since we put all our efforts on another model around this time, I was not able to investigate further training a model to transform the semantic embeddings, but this idea nonetheless offers an alternative perspective on what an editing model could be: a translation into a hierarchical semantic embedding of an image, followed by a second model that transforms that embedding, with all editing at this level of the embedding, and the diffusion model strictly frozen.
Since our focus as a company moved onto training a unified new diffusion model after this phase, I did not further train transformations of the embeddings — but these T5 experiments verified that instruct-style editing purely in the semantic embeddings space is possible.
Further directions
With a stronger decoder LLM in placed in this architecture instead of the T5, the potential exists for a novel kind of natural image editing, where — instead of the common approaches that rely on using trade-offs between fidelity to source image versus modification, configure by volatile inference-time parameters — a semantic but also spatial representation of the image becomes the domain of manipulation by an LLM, keeping the diffusion model strictly as a decoder.
Additionally, if photo-level fidelity to the base image is desired in the small details, a simple variation on this architecture could be trained, which I began to explore: during the decoding phase in the diffusion model, permit attention directly to the source image’s vae-encoded latents, but modulated by the similarity of embeddings at each patch location. This setup would require some minor tuning of the diffusion model, but could permit patches that are matching or largely unchanged in the edited target image to attend to their contents in the source image during decode, increasing fidelity to details substantially.